
中国团队拿下ICRA'26最佳论文:Agentic Coding驱动工业制造通往自主通用智能
中国团队拿下ICRA'26最佳论文:Agentic Coding驱动工业制造通往自主通用智能刚刚,在维也纳落幕的机器人顶会ICRA 2026上,最佳论文奖(自动化方向)颁给了一支中国团队。
来自主题: AI技术研报
6596 点击 2026-06-24 09:54
 搜索
搜索
刚刚,在维也纳落幕的机器人顶会ICRA 2026上,最佳论文奖(自动化方向)颁给了一支中国团队。
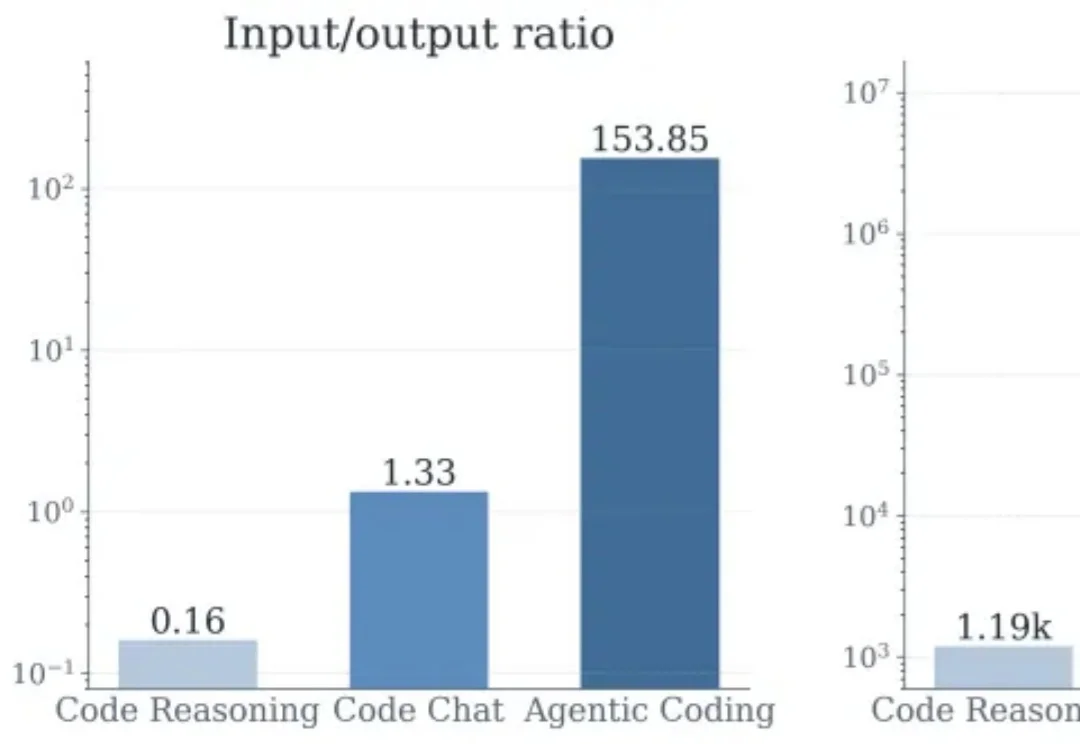
如今的 AI Agent 正在大规模落地,其中应用最广且最受关注的当数 Claude Code,Codex,Cursor 这类 coding agent。过去的一年里,这类 coding agent 产品迭代迅速,在一年内将在 swe-bench- verified 的准确率提高到了 78%+。

Agentic Coding 评测里 V4-Pro 已经到当前开源最佳水平。DeepSeek 公司内部已经把 V4 作为默认编码模型,反馈是优于 Sonnet 4.5,交付质量接近 Opus 4.6 的非思考模式,和 Opus 4.6 的思考模式还有差距。这次还专门为 Claude Code、OpenClaw、OpenCode、CodeBuddy

全球最强编程模型,中国造。
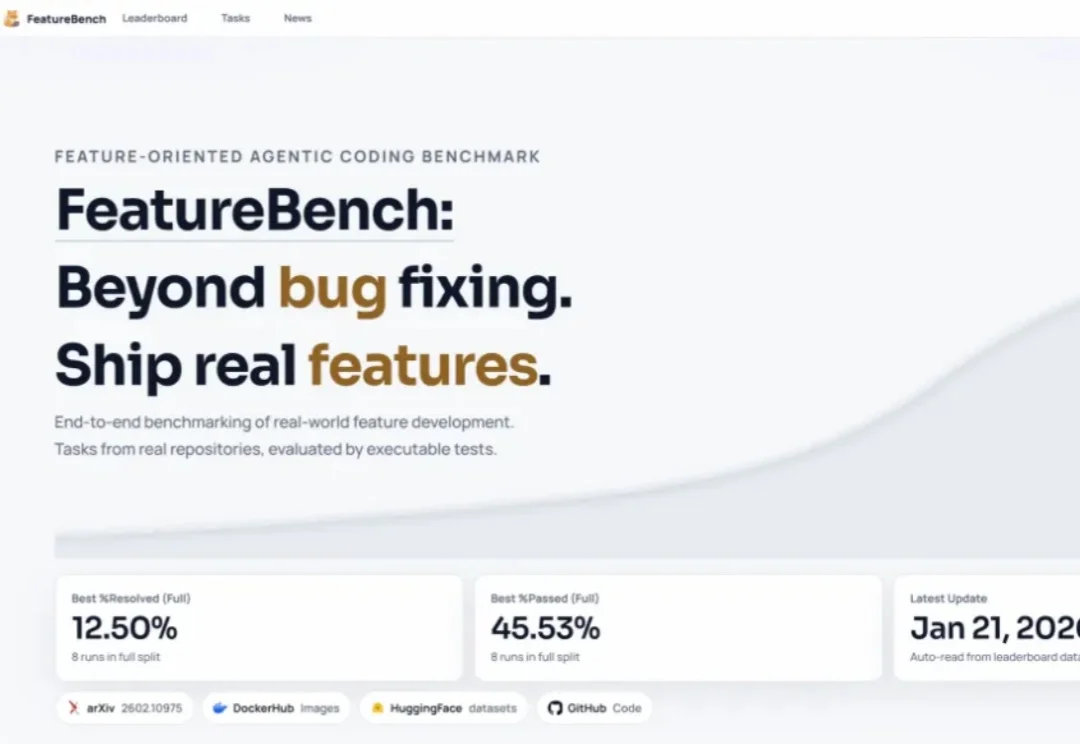
在 Princeton 发布 SWE-Bench 之后,用真实世界代码仓库+可执行测试评测大模型软件工程能力,几乎已成为学术界与工业界的共识。围绕 SWE issue 的评测范式迅速发展,也催生了一系列 SWE 系列 benchmark,在刻画模型 bug 修复能力方面发挥了重要作用。

开源模型同样能承担复杂工程任务。

“很正确,无比正确” 当我们问起阿里巴巴 Qoder[1] (Agentic Coding 产品)创始人叔同,关于他带领团队冲入全球 AI Coding 这片“红海” 60 天后的感受时,他给出了这样简单而坚定的回答。他的底气,源自一份优秀的成绩单:上线 5 天用户迅速突破 10 万,仅 60 天斩获 50 万开发者用户。
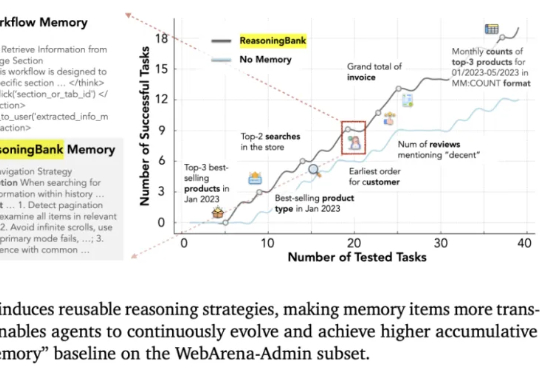
这几天,关于「微调已死」的言论吸引了学术圈的广泛关注。一篇来自斯坦福大学、SambaNova、UC 伯克利的论文提出了一种名为 Agentic Context Engineering(智能体 / 主动式上下文工程)的技术,让语言模型无需微调也能实现自我提升!
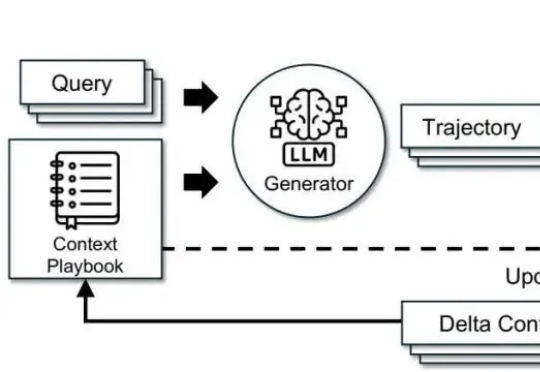
调模型不如“管上下文”。这篇文章基于 ACE(Agentic Context Engineering),把系统提示、运行记忆和证据做成可演化的 playbook,用“生成—反思—策展”三角色加差分更新,规避简化偏置与上下文塌缩。在 AppWorld 与金融基准上,ACE 相较强基线平均提升约 +10.6% 与 +8.6%,适配时延降至约 1/6(-86.9%),且在无标注监督场景依然有效。
智东西9月5日消息,刚刚,大模型独角兽月之暗面发布新模型Kimi K2-0905,目前,Kimi应用和网页版中的K2模型已全量升级到Kimi K2-0905。该模型的核心升级点为Agentic Coding能力增强、支持256K上下文、API支持高达60-100Token/s的输出速度、支持Claude Code。